Profiling Golang applications using pprof
In the last few weeks, Codenation has been experiencing very significant growth. Confirming the sentence of the great Bruno Ghisi who says that “on the scale everything breaks”, features that always worked perfectly become problematic.
We noticed in the metrics of our Prometheus that one of the endpoints of our API was consuming a lot of resources. Talking to the team we came up with a suspicious reason, but before I refactored the code, I thought it would be better to do a more “scientific” analysis.
As we developed our API in Go, famous for its impressive collection of native tools, I started the analysis using the “official” solution, pprof.
Since the focus of the analysis was on a specific endpoint, I changed the application code:
func privateJourneyFindAll(services *core.Services) http.Handler {
return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
f, err := os.Create("privateJourneyFindAll.prof")
if err != nil {
log.Fatal(err)
}
pprof.StartCPUProfile(f)
defer pprof.StopCPUProfile()
//rest of code, unchanged
This change creates a file with the data that we can analyze later. I’m only looking at CPU consumption, which was the key problem in this case, but pprof allows you to collect more metrics, as seen in the package’s documentation.
After the change, we can compile the application:
go build -o ./bin/api api/main.go
When accessing the endpoint using the interface or curl will create the file privateJourneyFindAll.prof.
We can now do the analysis, executing the command:
go tool pprof bin/api privateJourneyFindAll.prof
We need to specify the location of the binary, and also the data file. The command will start a prompt:
File: api
Type: cpu
Time: Apr 8, 2020 at 8:38am (-03)
Duration: 660.56ms, Total samples = 90ms (13.62%)
Entering interactive mode (type "help" for commands, "o" for options)
(pprof)
At this prompt we can execute some commands, such as:
(pprof) top10
Showing nodes accounting for 90ms, 100% of 90ms total
Showing top 10 nodes out of 72
flat flat% sum% cum cum%
20ms 22.22% 22.22% 40ms 44.44% runtime.mallocgc
20ms 22.22% 44.44% 20ms 22.22% runtime.memclrNoHeapPointers
10ms 11.11% 55.56% 10ms 11.11% reflect.Value.assignTo
10ms 11.11% 66.67% 10ms 11.11% runtime.madvise
10ms 11.11% 77.78% 10ms 11.11% runtime.memmove
10ms 11.11% 88.89% 10ms 11.11% runtime.pthread_cond_wait
10ms 11.11% 100% 10ms 11.11% syscall.syscall
0 0% 100% 20ms 22.22% github.com/codegangsta/negroni.(*Logger).ServeHTTP
0 0% 100% 20ms 22.22% github.com/codegangsta/negroni.(*Negroni).ServeHTTP
0 0% 100% 20ms 22.22% github.com/codegangsta/negroni.HandlerFunc.ServeHTTP
(pprof)
There are other commands, but the most interesting is:
(pprof) web
(pprof)
This command will open your default browser with a tree view of your application’s execution, as in the example below.
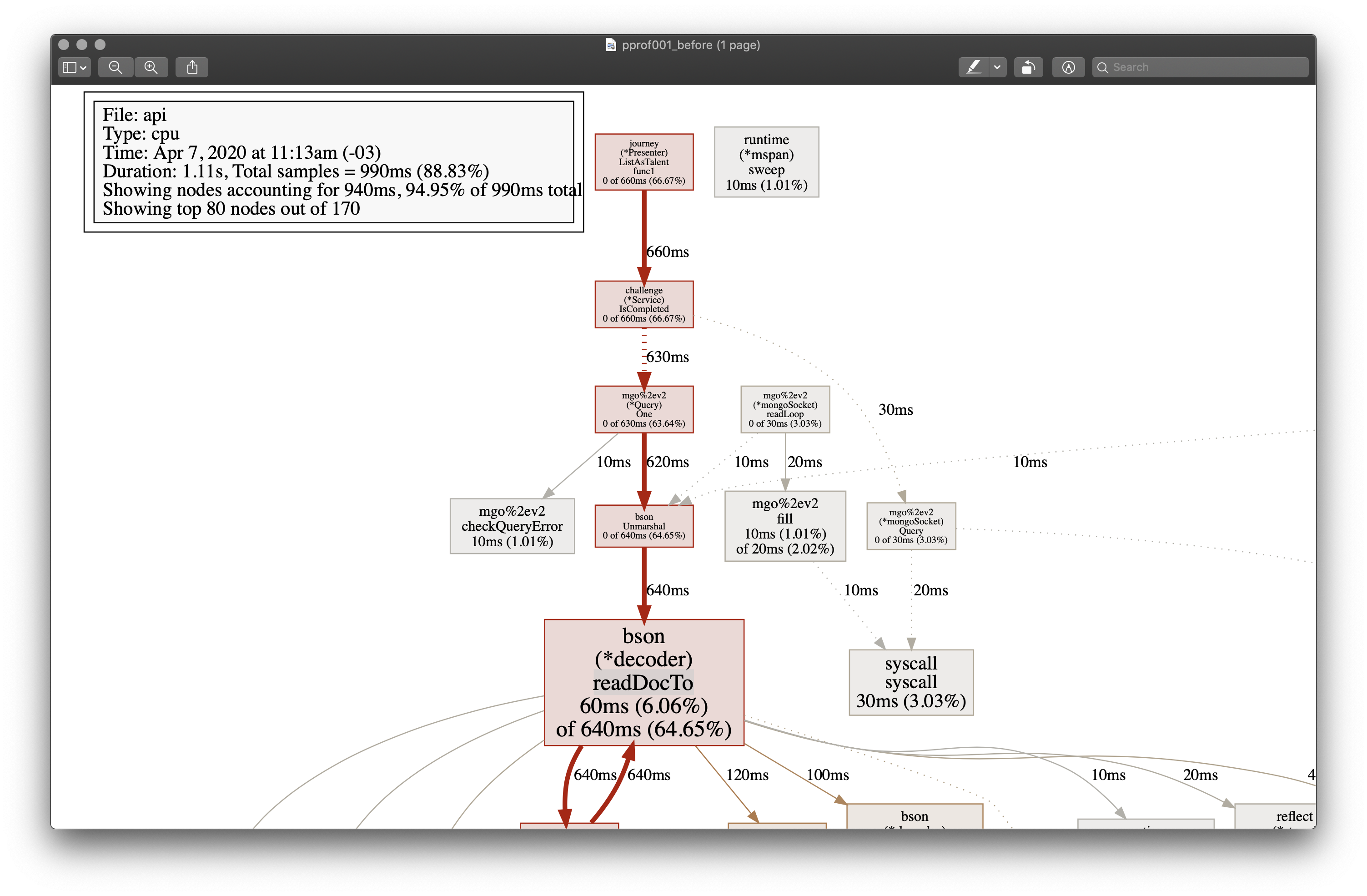
NOTE: I made a cut of the original image, to focus only on the important part for this post.
The two most important points in the image are the duration of 1.11 seconds and the red path formed by the functions ListAsTalent and IsCompleted, which are the bottleneck of the endpoint, proving the team’s initial suspicion.
After spending a few hours of refactoring and testing, I generated the profiling again with the updated version, and the result was much better:
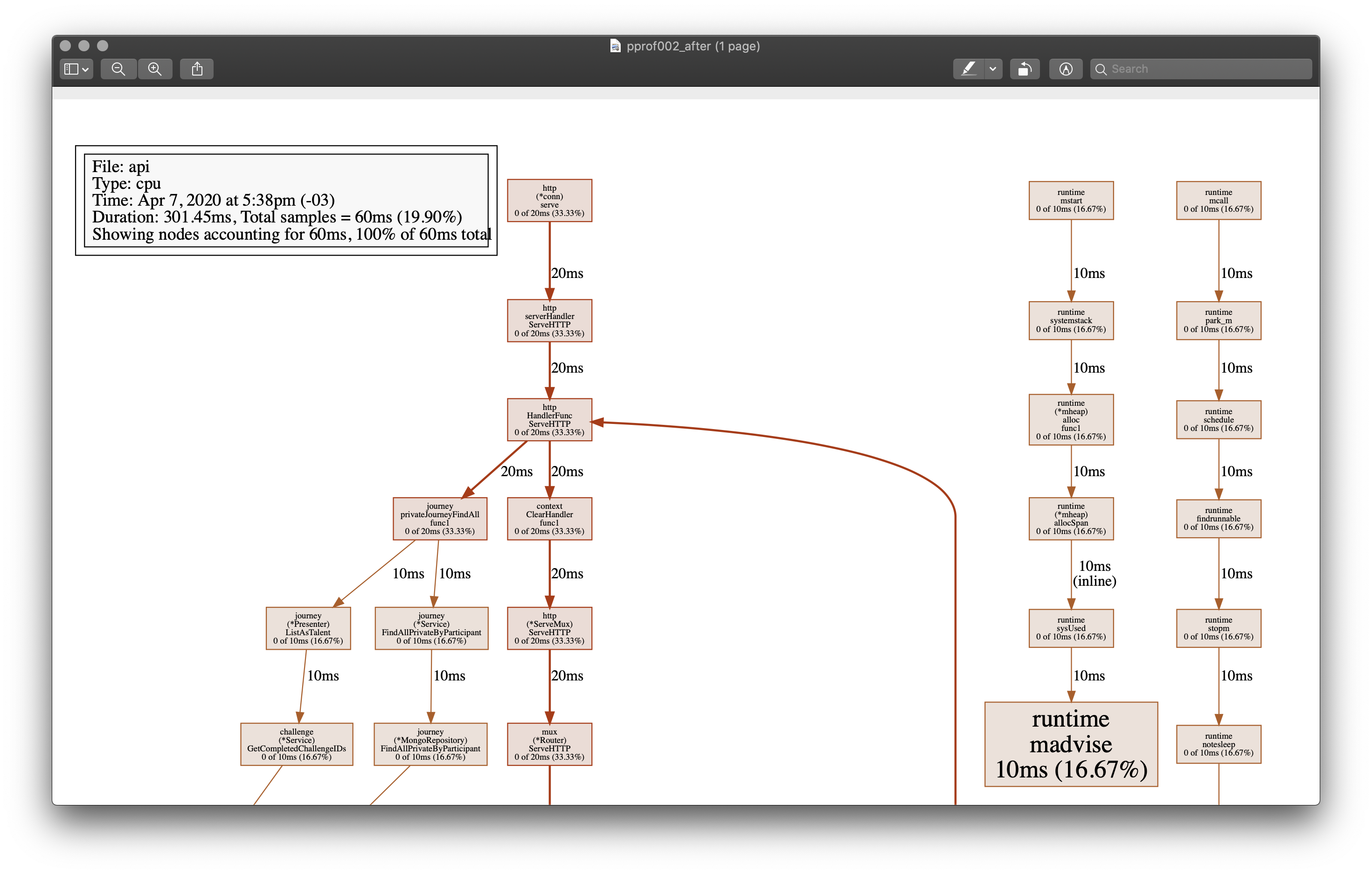
Now time has dropped to 301.35 milliseconds and the tree is much better balanced, with no critical paths as before.
NOTE: before committing the change I removed the codes related to the profiling generation. In the post about pprof that I mentioned before, you can see more advanced techniques to enable/disable this feature, using flags and parameters.
Thanks to the profiling generated by pprof it was much faster to find the bottleneck of the application, allowing us to focus exactly where the problem was.