Observabilidade como o pilar de grandes arquiteturas
Contents
Este post é baseado em uma palestra que apresentei no KCD Floripa 2024. Você pode conferir os slides e o video da apresentação, caso prefira este formato.
Quando pensamos em “observabilidade” provavelmente a primeira ideia que nos remete é “problemas”, ou melhor, “resolução de problemas” (troubleshooting se preferir o jargão). Mas neste post quero trazer outra visão sobre o tema: a observabilidade como uma pilar crucial para o desenvolvimento de grandes arquiteturas de software.
Meu objetivo com este texto é responder três grandes perguntas:
- O que é observabilidade?
- O que é uma grande arquitetura?
- Como garantir a existência destas arquiteturas?
Monitoramento x Observabilidade
Vamos começar pelo começo….
Monitoramento
Permite que as equipes observem e entendam o estado de suas APIs ou até mesmo sistemas. É baseado na coleta de conjuntos predefinidos de métricas ou logs
O monitoramento invoca uma visão de obscuridade, de podermos entender um sistema/software apenas a partir de suas entradas e saídas. Algo representado na imagem:
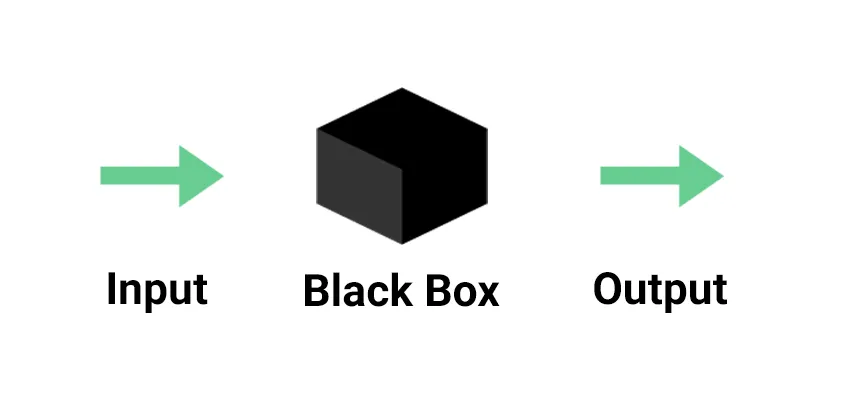
Com essa abordagem podemos definir monitoramentos como no exemplo:
- dado que a API recebe 1000 requisições no formato X, é esperado que ela gere 1000 respostas no formato Y.
Como a definição deixa claro: estamos olhando para conjuntos predefinidos de informações.
Observabilidade
É baseada na exploração de propriedades e padrões não definidos com antecedência. Invoca um sentimento de transparência, é uma forma de monitoramento baseado em métricas expostas pelo sistema.
A representação clássica de observabilidade é algo como:
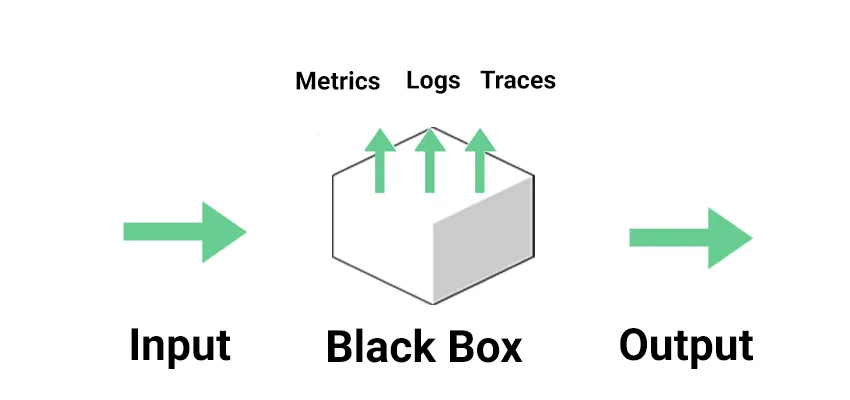
Agora deixamos de ver nosso sitema como uma caixa opaca e podemos ver “seu interior”, graças aos sinais que a própria aplicação gera.
Na imagem podemos ver os chamados “três pilares clássicos da observabilidade”:
- Metrics: Medições numéricas coletadas e rastreadas ao longo do tempo.
- Logs: Uma transcrição detalhada do comportamento do sistema
- Traces: uma rota de interações entre componentes, juntamente com um contexto associado;
Mas algumas referências recentes expandem o conceito trazendo novos sinais:
- Events: snapshots de mudanças de estado significativas;
- Profiles: método para inspecionar dinamicamente o comportamento e o desempenho do código do aplicativo em tempo de execução;
- Exceptions: uma forma especializada de logs estruturados. Este é um sinal que não é tão comum em documentações, sendo muitas vezes considerado apenas como uma versão de um Log. Mas achei interessante mantê-lo neste documento pois pode fazer sentido para alguns cenários.
AWS Well-Architected Framework
Se perguntarmos a diferentes pessoas “o que define uma boa arquitura?” devemos ter respostas também diferentes. Isso devido ao fato que existem diferentes visões e definições para esta resposta. Neste post vou adotar uma das possibilidades, o framework desenvolvido pela AWS para definir aplicações que fazem melhor uso dos conceitos de Cloud Native em suas arquiteturas.
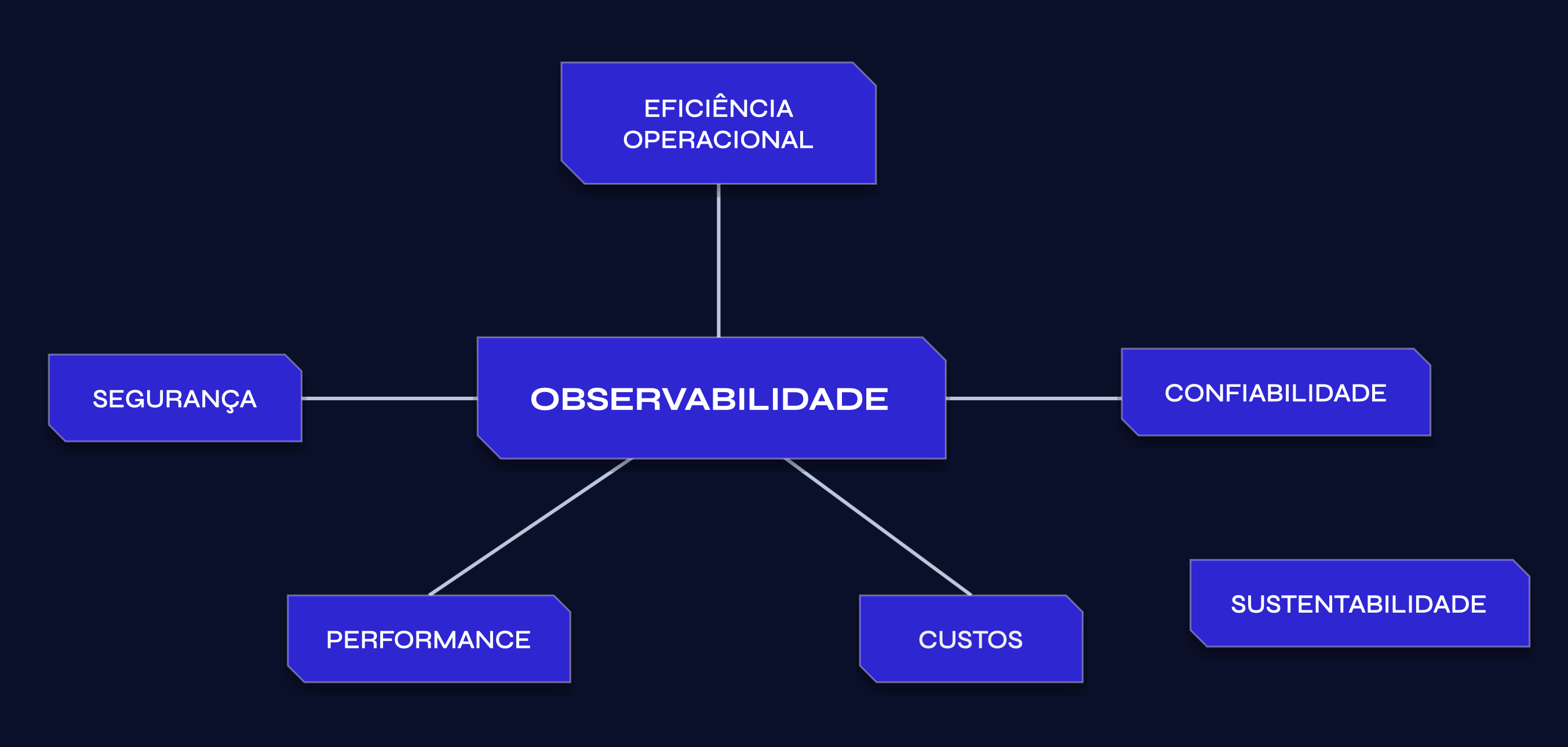
O framework define alguns pilares:
- Excelência operacional: se concentra na execução e monitoramento de sistemas e na melhoria contínua de processos e procedimentos
- Segurança: se concentra na proteção de informações e sistemas
- Confiabilidade: se concentra nos workloads que executam as funções pretendidas e na recuperação rápida de falhas em atender demandas
- Eficiência de performance: se concentra na alocação estruturada e simplificada de recursos de TI e computação
- Otimização de custos: se concentra em evitar custos desnecessários
- Sustentabilidade: se concentra em minimizar os impactos ambientais da execução de workloads em nuvem
Apesar de ser desenvolvido pela AWS, os conceitos descritos podem ser aplicados para aplicações em qualquer ambiente, até nos on premise.
Mas onde a observabilidade se encaixa neste framework? Na minha visão a observabilidade encontra-se no centro da maioria destes pilares:
Para detalhar o que eu entendo desta interconexão, criei uma tabela fazendo a correlação entre os pilares de observabilidade e os do framework da AWS:
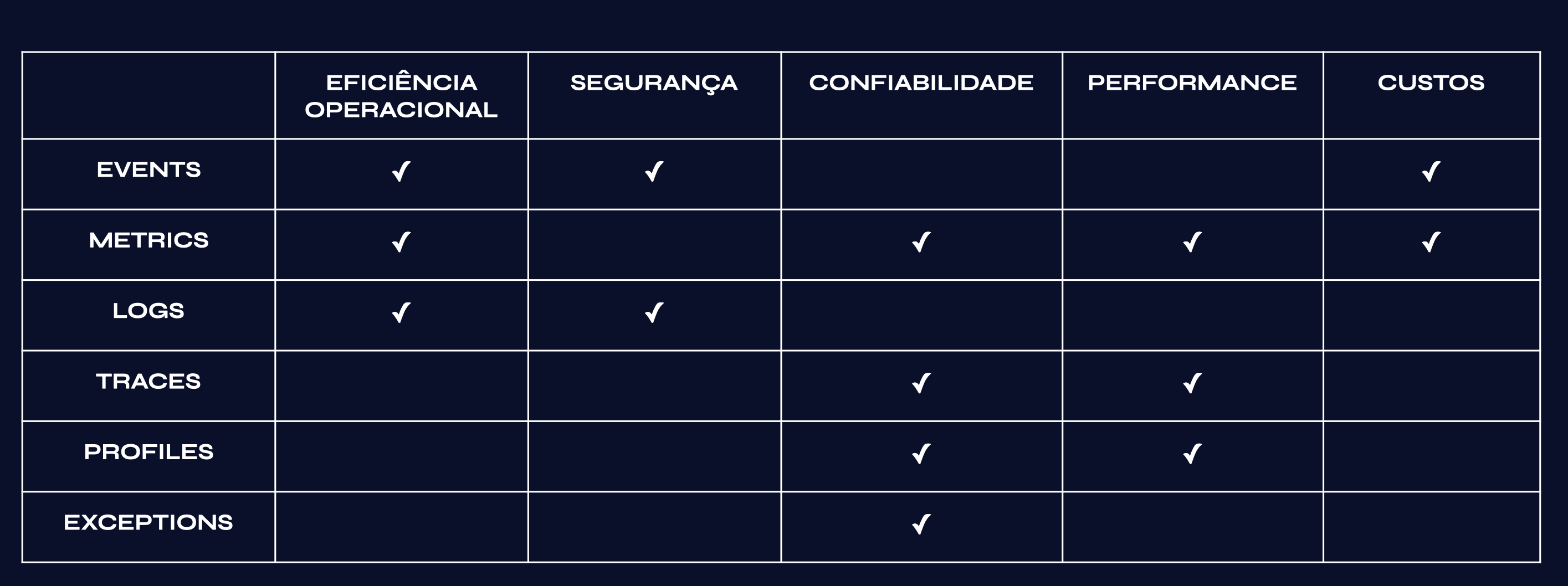
Por exemplo, para garantir o pilar de Eficiência de performance é necessário fazer uso de métricas, traces e profiles. Enquanto que o pilar de Otimização de custos consegue ser observado usando-se eventos e métricas.
E como garantir uma grande arquitetura?
Para responder essa pergunta quero sugerir duas abordagens complementares.
Fitness Functions
O termo foi cunhado pela primeira vez no livro Building Evolutionary Architectures e usado novamente no Arquitetura de Software: as Partes Difíceis: Análises Modernas de Trade-off Para Arquiteturas Distribuídas e sua definição fala que:
“Descrevem o quão próxima uma arquitetura está de atingir um objetivo arquitetônico. Durante o desenvolvimento orientado a testes, escrevemos testes para verificar se os recursos estão em conformidade com os resultados comerciais desejados; com o desenvolvimento orientado a funções de aptidão (fitness functions), também podemos escrever testes que medem o alinhamento de um sistema com os objetivos arquitetônicos."
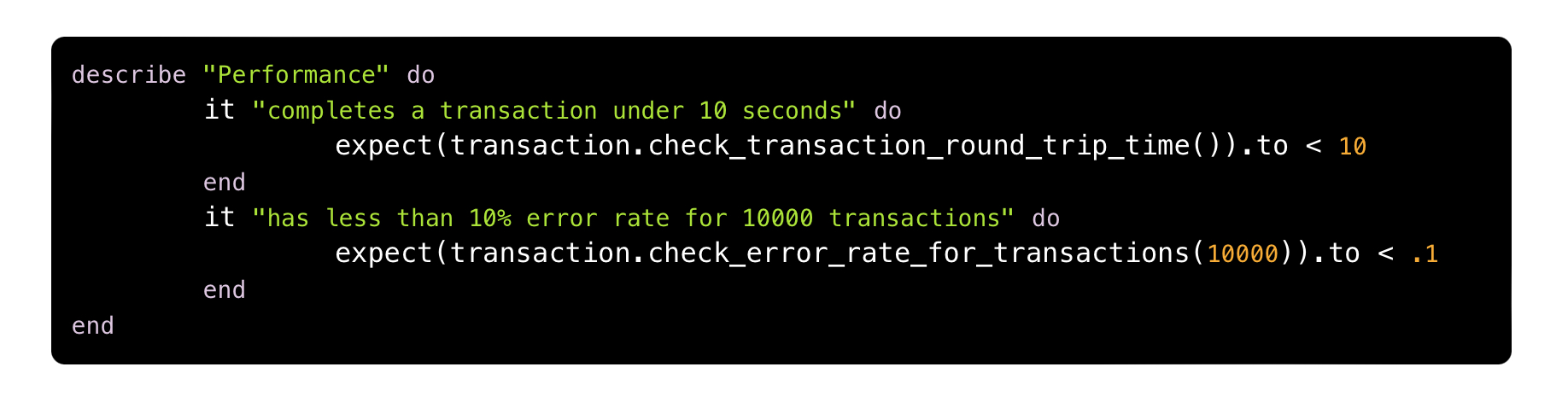
Desta forma, vamos imaginar uma fitness function para validar a performance de uma arquitetura:

Um possível pseudo-código para este teste poderia ser descrito da seguinte forma:
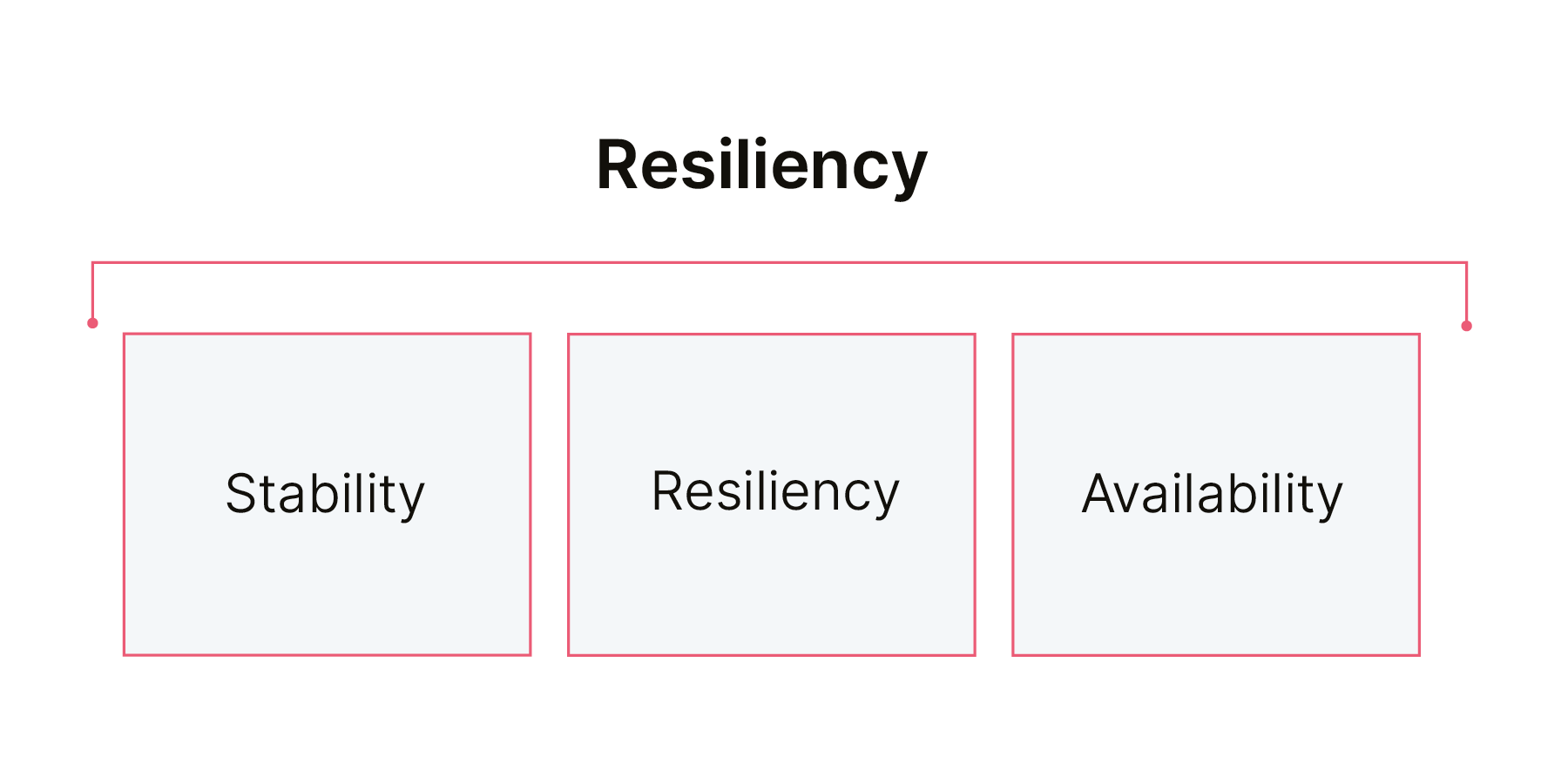
Outro exemplo seria a validação do requisito de resiliência:
Cujo pseudo-código seria:
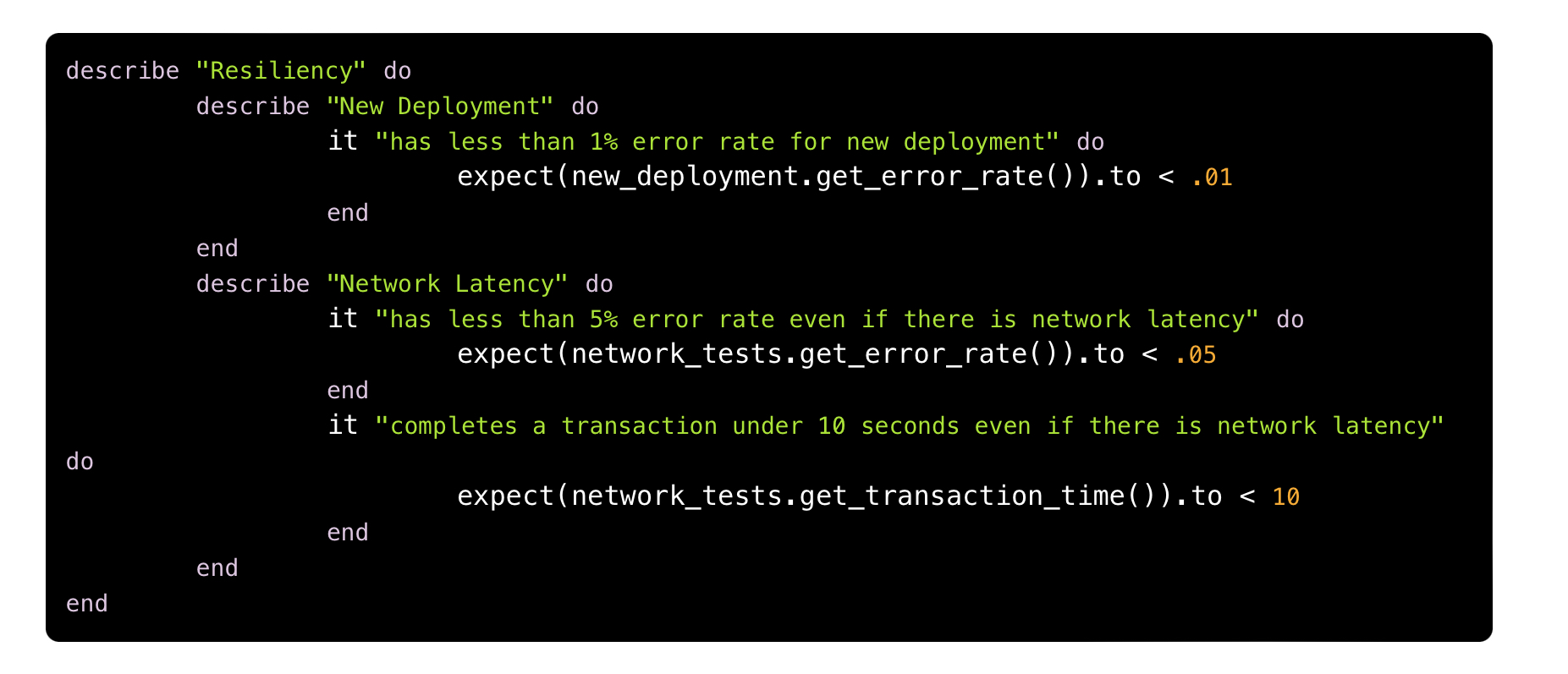
Em ambos os exemplos só conseguimos fazer as validações graças ao uso de métricas (transaction.check_error_rate_for_transaction e network_tests.get_transaction_time para citar dois), um dos pilares clássicos de observabilidade.
Observability-driven development
A outra forma de garantir que nossa arquitetura cresça de forma saudável é usando o conceito de ODD (Observability-driven development), que pode ser descrito como:
ODD é um “shift left” de tudo relacionado à observabilidade para os estágios iniciais do desenvolvimento.
Um comportamento que já vi se repetir em alguns projetos é o time fazer a implementação e nos últimos estágios (geralmente quando começam a ser identificados problemas em ambientes de QA ou até em prod) começar a instrumentar a aplicação, incluindo logs, métricas e traces. O ODD propõe trazer as discussões sobre observabilidade para os primeiros estágios do ciclo de desenvolvimento.
ODD tem similaridades com outra sigla famosa, o TDD (Test-driven development), sendo suas diferenças principais:
- TDD: enfatiza a escrita de casos de teste antes de escrever o código para melhorar a qualidade e o design
- ODD: enfatiza a escrita de código com a intenção de declarar as saídas e os limites de especificação necessários para inferir o estado interno do sistema e do processo, tanto no nível do componente quanto como um sistema completo
O diagrama a seguir coloca as duas técnicas em perspectiva:
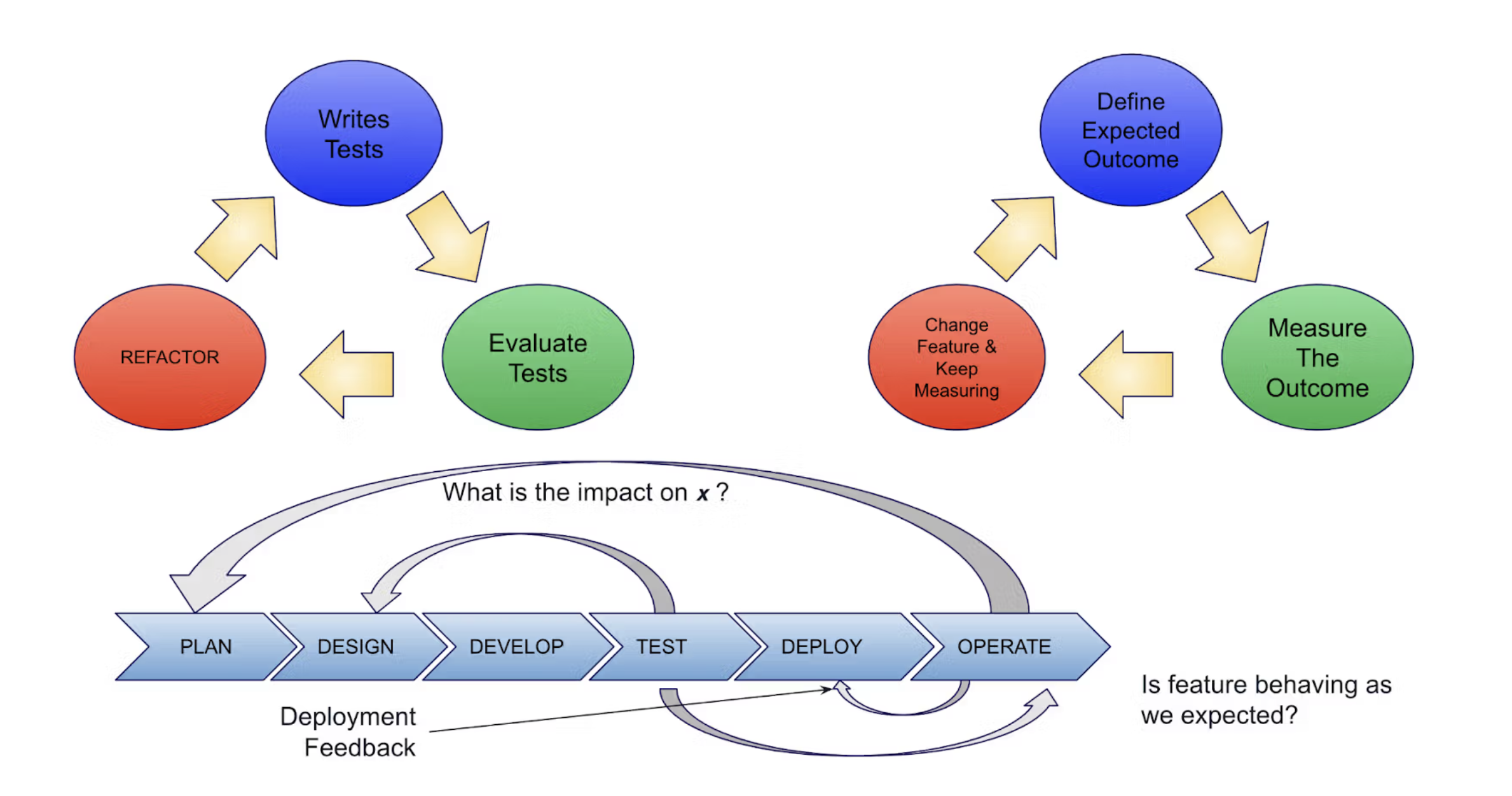
Enquanto o TDD criou um ciclo de feedback entre o teste e o design, o ODD expande os ciclos de feedback, garantindo que os recursos se comportem conforme o esperado, melhorando os processos de implantação e fornecendo feedback para o planejamento.
Conclusão
Recaptulando os primeiros parágrafos deste texto, vamos revisar as três perguntas que propus e suas respostas:
O que é observabilidade? Metrics, Logs, Traces, e os demais pilares
O que é uma grande arquitetura? Trouxe o AWS Well-Architected Framework como uma das possíveis formas de definição
Como garantir a existência destas arquiteturas? Apresentei duas formas, usando as fitness functions e ODD
Espero também ter trazido a perspectiva de que observabilidade vai além de uma série de ferramentas e conceitos a serem usados em momentos de troubleshooting mas também como algo a ser cultivado para garantir o desenvolvimento de arquiteturas de software eficientes.